Forscher erweitern genetischen Code
Max-Planck-Wissenschaftlern gelingt es, zusätzliche synthetische Aminosäuren in die Translationsmaschinerie lebender Zellen einzubauen und maßgeschneiderte Proteine zu erzeugen
Die Erforschung der Proteinsynthese und ihrer Steuerung durch den genetischen Code ist seit langem ein zentrales Thema in der Biologie. Inzwischen kennt man fast alle wichtigen Komponenten der Proteinsynthese in lebenden Zellen einschließlich der Struktur des Ribosoms. Im Schatten dieser Entwicklung haben Proteinchemiker Wege gefunden, wie man die Proteinsynthese in lebenden Zellen umprogrammieren und den genetischen Code durch "künstliche" Aminosäuren erweitern kann. Wissenschaftlern des Max-Planck-Instituts für Biochemie ist es gelungen, E. coli-Bakterien unter Selektionsdruck dazu zu bringen, synthetische Aminosäuren ihrem genetischen Code hinzu zu fügen und neue Klassen von fluoreszierenden Proteinen zu erzeugen: Durch den Einbau einer Elektronen-spendenden Aminogruppe in das bekannte "Grün-fluoreszierende Protein" entstand auf diese Weise ein "Gold-fluoreszierendes Protein", ein lang erwartetes Werkzeug für dynamische biophysikalische Untersuchungen von Zellen und Geweben. Durch Hinzufügen neuer Aminosäuren zum genetischen Code lassen sich somit neuartige Proteine mit maßgeschneiderten physikalisch-chemischen Eigenschaften und Funktionen erzeugen, die in der Natur nicht vorkommen. Mit diesem "Engineering des genetischen Codes" eröffnen sich einerseits völlig neue Forschungsthemen, wie die Entwicklung "synthetischer Lebensformen", von "Teflon-Proteinen", dem "de novo Protein-Design" sowie vielfältige Anwendungen. Damit ergeben sich aber andererseits auch ganz neue moralisch-ethische und philosophische Fragestellungen (Angewandte Chemie, Online-Edition 1. Dezember 2004).
Der genetische Code schreibt vor, wie die in der DNS gespeicherten Erbinformationen in die Aminosäuresequenzen der Proteine zu übersetzen sind. Hierbei gibt es eine auffällige Besonderheit - alle auf der Erde lebenden Organismen kommen mit denselben 20 Aminosäuren als grundlegenden Bausteinen für ihre Proteinsynthese aus. Doch in diesem "kanonischen Repertoire" des genetischen Codes fehlen viele interessante Aminosäureverbindungen, die Atome wie Fluor, Chlor, Brom, Selen, Silizium oder interessante chemische Gruppen (cyano-, azido-, nitroso-, nitro- usw.) enthalten. Mit diesen Bausteinen ließen sich ganz neue Klassen von therapeutischen oder diagnostischen Proteinen herstellen, aber auch nicht-invasive protein-basierte Sensoren, neue umweltfreundliche Materialien, usw.
. Rechts dagegen sind Kolibakterien, deren genetische Code-Interpretation so geändert ist, dass sie statt Tryptophan die synthetische Aminosäure Amino-Tryptophan in das Zielprotein einbauen. Die Wirtszellen und das entsprechende Protein fluoreszieren \"goldfarben\" (Gold-fluoreszierendes Protein).
© Max-Planck-Institut für Biochemie")
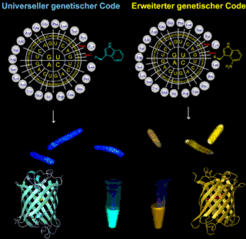
Erste Versuche zeigen, dass die Zahl der Aminosäuren in der Proteinsynthese weit über die kanonischen Zwanzig hinaus ausgedehnt werden kann. Das ist aber nur möglich, wenn man entweder die Interpretation des genetischen Codes verändert oder die Kodierungskapazität durch zusätzliche Aminosäuren erweitert (vgl. Abbildung 2). Damit entsteht am Schnittpunkt von synthetischer Chemie und Molekularbiologie ein völlig neues Forschungsgebiet, das "Engineering des genetischen Codes".
Wissenschaftler um Nediljko Budisa am Max-Planck-Institut für Biochemie in Martinsried haben bereits viele Beispiele verwirklicht, wie Proteine mit nichtkanonischen Aminosäuren von der Biomedizin bis zur Strukturgenomik nutzbringend eingesetzt werden können. Das "Gold-fluoreszierende Protein" ist ein besonders überzeugendes Beispiel, wie mächtig diese Technologie für das Design von maßgeschneiderten Proteinen ist. "Während die Entzifferung des genetischen Codes eine Folge der intensiven Wechselwirkungen zwischen organischer Chemie und Genetik in den 60er Jahren des letzten Jahrhunderts war, wird die gegenwärtige ‚Ehe’ zwischen Chemie und Molekularbiologie zu einer ‚Code-Evolution im Labor’ führen", behauptet Nediljko Budisa, Leiter einer Forschungsgruppe am Max-Planck-Institut für Biochemie.
Die Konservierung von zwanzig Grundbausteinen im jetzigen Code ist die Folge einer evolutionären Entwicklung, d.h. ein eher historisches Ereignis, gestaltet durch ein Spiel von Zufall und Notwendigkeit. Es mag sein, dass der jetzige Code "der bestmögliche" für alle Lebewesen auf der Erde ist, aber sicher nicht der bestmögliche für unsere technischen und technologischen Bedürfnisse. Die jetzige Codestruktur bietet genug Raum für eine erfolgreiche Repertoire-Erweiterung. Da die effiziente Reprogrammierung des Translationsapparats eine wichtige Voraussetzung für die Biotechnologie der Zukunft ist, müssen wir die weitere Code-Evolution in unsere Hände nehmen."
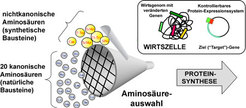
 können in der Regel alle 20 kanonischen Aminosäuren selbst herstellen. Durch Einsatz von metabolisch veränderten Wirtszellen (bei denen z.B. ein oder mehrere Gene für die Aminosäureherstellung verändert sind) kann die Aminosäureauswahl für die Proteinsynthese beeinflusst werden. Solche Zellen können neue nichtkanonische Aminosäuren selbst produzieren oder direkt aus dem Nährmedium aufnehmen. Diese neuen Proteinbausteine für die Proteinsynthese werden durch Aminoacyl-tRNA-Synthetasen, eine Familie von 20 Enzymen, deren Hauptaufgabe die Interpretation des genetischen Codes ist, selektiert. Diese Enzyme müssen auch oft entsprechend verändert (designed) werden, damit sie die gewünschte Aminosäure in Substrate für die Proteinsynthese umwandeln. In der Regel ist eine erfolgreiche Erhöhung der Anzahl der Aminosäurebausteine nur durch Kombination des Engineering dieser Enzyme mit der Umsteuerung des Metabolismus in der entsprechenden Wirtszelle möglich.
© Max-Planck-Institut für Biochemie")
Das Engineering des genetischen Codes hat sich in den vergangenen Jahren zu einem Top-Forschungsgebiet in der Proteinchemie und Biologischen Chemie entwickelt. Budisa betont: "Damit stellen sich auch völlig neue Fragen nach der "ersten künstlichen Lebensform", nach "Teflon-Proteinen", einem de novo Proteindesign, dem Potential von Aminosäure-Surrogaten in der Neurobiologie oder Aspekten der Evolutionstheorie. Diese Forschungsrichtung wird also nicht nur zu neuem technischem Fortschritt führen, sondern auch eine weitere Dimension in traditionelle philosophische, moralische und ethische Debatten bringen."
Bisherige Entwicklung des "Engineering des genetischen Codes"
. Solche Proteine besitzen oft neuartige Eigenschaften, die unseren technischen oder technologischen Bedürfnissen dienen können, deshalb bezeichnet man sie als \"maßgeschneidert\" (costum made) für diese Zwecke. Auf der Ebene des genetischen Codes führen solche Versuche zu einer erfolgreichen Änderung der Deutung (Interpretation) des genetischen Codes (z.B. ist die Codierungseinheit UGG für die kanonische Aminosäure Tryptophan (Trp; Zyan) neu dem nichtkanonischen Baustein Amino-tryptophan (orange) zugeordnet). Diese neuen Proteinbausteine bilden eine alternative oder synthetische Kodierungsstufe in der Struktur des genetischen Codes.
© Max-Planck-Institut für Biochemie")

Derartige Überlegungen sind so alt wie die Molekularbiologie selbst. Schon in den 1950er Jahren gelang es in den klassischen Versuchen von Georges Cohen und Dean Cowie am Pasteur-Institut in Paris, einen Kolibakterien-Stamm zu identifizieren, der in der Lage war, statt der kanonischen Aminosäure Methionin eine ähnliche Verbindung (Analoga), Selenomethionin, in die eigenen Proteine einzubauen. Dieser Bakterien-Stamm war ‚auxotroph’, das heißt nicht fähig, den Baustein Methionin selbst herzustellen, aber er konnte diesen aus seiner Umwelt (Nährmedium) beziehen. Das ermöglichte eine Zwangsfütterung der Bakterien mit Selenomethionin. Und vor zwanzig Jahren hat J. T. Wong in Kanada einen Bacillus-Bakterienstamm mit einer Vorliebe für nichtkanonische Aminosäuren erfolgreich genetisch selektiert. Diesen Stamm bezeichnete er als den "ersten freilebenden Organismus in den letzten paar Milliarden Jahren, der zügig gelernt hat, wie man erfolgreich vom universalen genetischen Code abweichen kann".
Heute setzt man genetisch manipulierte Zellen - in Kombination mit rekombinanter DNA-Technologie - gezielt einem starkem Selektionsdruck aus. Auf diese Weise kann eine große Zahl neuer Bausteine, also nichtkanonischer Aminosäuren, durch Adaptermoleküle (t-RNA) in eine Proteinsequenz übersetzt werden (vgl. Abbildung 2 und 3). In letzter Zeit konzentriert man sich auf die Weiterentwicklung eines Hybrid-Translationssystems, um die Zahl der nichtkanonischen Aminosäuren, die als Substrate für die ribosomale Proteinsynthese dienen können, weiter zu erhöhen.
So haben vor kurzem Marliere und Mitarbeiter vom Pasteur-Institut in Paris einen Kolibakterien-Stamm mit defekter Lesekorrekturfunktion konstruiert, in dessen zellulärem Proteom fast 24 Prozent des kanonischen Bausteins Valin durch die nichtkanonische amino-butyrische Säure ersetzt sind. Parallel dazu gelang es Tirrel und Mitarbeitern in Pasadena, USA, ein verbessertes Translationssystem mit einer erhöhten intrazellulären Anzahl von Aminoacyl-tRNA-Synthetasen als essentielle Enzyme für die Proteintranslation zu entwickeln. Die wohl weitreichendste methodische Entwicklung auf diesem Gebiet haben Wissenschaftler um P. G. Schultz in La Jolla, Novartis Institut für Genomforschung, erreicht. Diese Gruppe entwickelte nicht nur effiziente orthogonale tRNAs, sondern auch ein ausgefeiltes System aus kombinierter genetischer Selektion und Screening, das eine schnelle Evolution der Substratspezifität von Aminoacyl-tRNA-Synthetasen erlaubt, so dass eine große Anzahl nichtkanonischer Aminosäuren eingebaut werden kann.
Andere Ansätze auf diesem Gebiet sind die Kopplung des orthogonalen Translationssystems mit metabolischem Engineering, wodurch lebende Zellen, wie Bakterien, umprogrammiert werden können, so dass sie maßgeschneiderte Proteine ausschließlich mit Wasser, Salzen, Spurenelementen und einfachen Kohlenstoffquellen als Ausgangsmaterialien herstellen. Der jüngste Fortschritt auf diesem Gebiet ist die Einführung von modifizierten Translationskomponenten in eine eukaryotische Zelle (Hefe).